New optimization for time series data in Apache Phoenix 4.6
Today's blog is brought to you by Samarth Jain, PMC member of Apache Phoenix, and Lead Member of the Technical Staff at Salesforce.com.
Apache Phoenix 4.6 now provides the capability of mapping a Phoenix primary key column to the native row timestamp of Apache HBase. The mapping is denoted by
the keyword ROW_TIMESTAMP in the create table statement. Such a mapping
provides the following two advantages:
- Allows Phoenix to set the min time range on scans since this column directly maps to the HBase cell timestamp.
Presence of these time ranges lets HBase figure out which store files it
should be scanning and which ones to skip. This comes in handy
especially for temporal data when the queries are focused towards the
tail end of the data. - Enables Phoenix to leverage the existing optimizations in place when querying against primary key columns.
Lets look at an example with some performance numbers to understand when a ROW_TIMESTAMP column could help.
Sample schema:
For performance analysis, we created two identical tables, one with the new ROW_TIMESTAMP qualifier and one without.
CREATE TABLE EVENTS_RTS (
EVENT_ID CHAR(15) NOT NULL,
EVENT_TYPE CHAR(3) NOT NULL,
EVENT_DATE DATE NOT NULL,
APPLICATION_TYPE VARCHAR,
SOURCE_IP VARCHAR
CONSTRAINT PK PRIMARY KEY (
EVENT_ID,
EVENT_TYPE,
EVENT_DATE ROW_TIMESTAMP))
The initial data load of 500 million records created data with the
event_date set to dates over the last seven days. During the load,
tables went through region splits and major compactions. After the
initial load, we ran a mixed read/write workload with writes (new
records) happening @500K records per hour. Each new row was created
with EVENT_DATE as the current date/time.
Three sets of queries were executed that filtered on the EVENT_DATE column:
- Newer than last hour's event data
- Newer than last two day's event data
- Outside of the time range of event data
For example, the following query would return the number of rows for the last hours worth of data:
SELECT COUNT(*) FROM EVENTS_RTS
WHERE EVENT_DATE > CURRENT_DATE() - 1/24
Below is the graph that shows variation of query times over the tail end of data (not major compacted) for the two tables
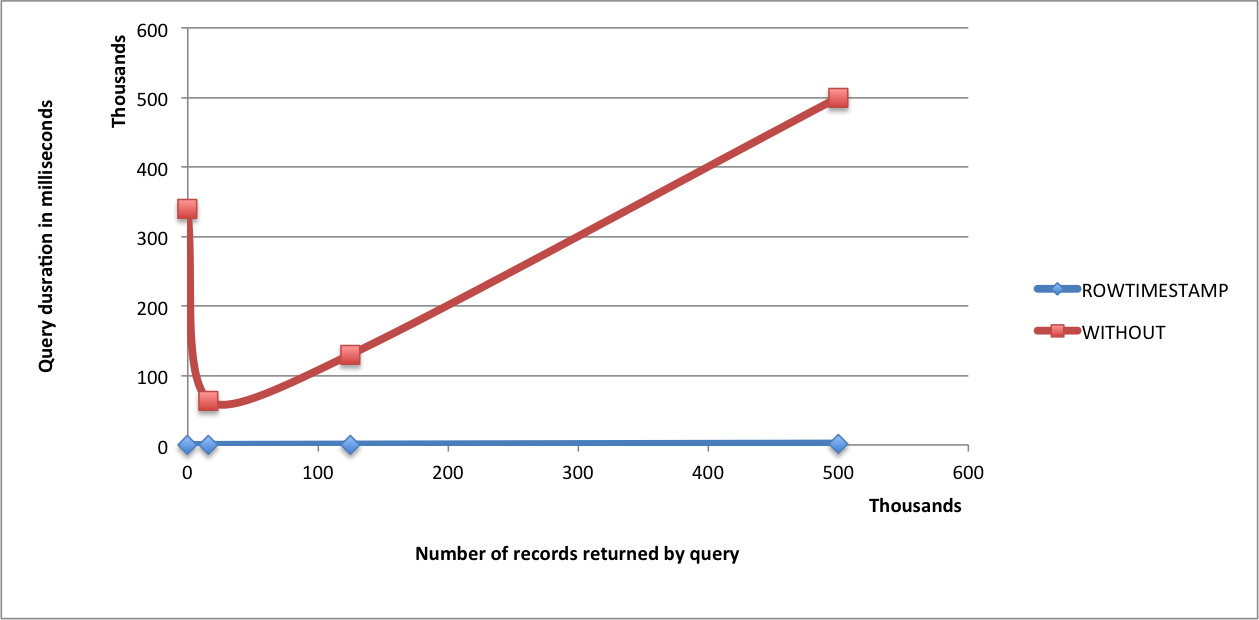
Below is a tabular summary of the various time ranges that were tested over the non-major compacted event data
| Time | # | Duration(ms) | |
|---|---|---|---|
| Range | Rows Returned | With Optimization | Without Optimization |
| CREATED IN LAST 1 MINUTE | 16K | 200 | 4000 |
| CREATED IN LAST 15 MINUTES | 125K | 700 | 130000 |
| CREATED IN LAST 1 HOUR | 500K | 2100 | 500000 |
| CREATED BEFORE LAST 8 DAYS | 0 | 100 | 340000 |
As you can see from the results, using a ROW_TIMESTAMP gives a huge perf
boost when querying over data that hasn’t been major compacted. For
already major compacted data, the two tables show the same performance
(i.e. there is no degradation). The query returning 0 records is a
special case in which the date range falls out of the data that was
loaded to the tables. Such a query returns almost instantaneously for
EVENTS_RTS (0.1 seconds). The same query on EVENTS_WITHOUT_RTS takes
more than 300 seconds. This is because with the time range information
available on scans, HBase was quickly able to figure out that no store
files have data within the range yielding a near instant response.
Effect of HBase major compaction
The HBase store file (HFile) stores time range (min and max row
timestamps) in its metadata. When a scan comes in, HBase is able to look
at this metadata and figure out whether it should be scanning the store
file for returning the records the query has requested. When writes are
happening to an HBase table, after crossing a threshold size, contents
of the memstore are flushed to an HFile. Now if the queries are against
the newly created (tail-end of data) HFiles, one would see a huge perf
boost when using the ROW_TIMESTAMP column. This is because, the scans
issued by Phoenix would need to read only these newly created store
files. On the other hand, queries not utilizing the row_timestamp column
will have to potentially scan the entire table.
The perf benefits are negated however, when HBase runs a major
compaction on the table. In the default compaction policy, when number
of HFiles exceeds a certain threshold or when a pre-determined time
period crosses, HBase performs a major compaction to consolidate the
number of store files in a region to one. This effectively ends up
setting the time range of the lone store file to all the data contained
within that region. As a result, scans are no longer able to filter out
what store files to skip since the lone store file happens to contain
all the data. Do note that in such a condition, the performance of the
query with the row_timestamp column is the same as the one without.
In conclusion, if your table has a date based primary key and your
queries are geared towards the tail-end of the data, you should think
about using a row_timestamp column as it could yield huge performance
gains.
Potential Future Work
One question you may be asking yourself is Why does performance drop after a major compaction occurs? I thought performance was supposed to improve after compaction. Time series data is different than other data in that it's typically write-once, append only. There are ways that this property of the data can be exploited such that better performance is maintained. For some excellent ideas along these lines, see Vladimir Rodionov's presentation from a previous HBase Meetup here.