Apache Ignite 2.0: Redesigned Off-heap Memory, DDL and Machine Learning
We released the long-awaited Apache Ignite version 2.0 on May 5. The community spent almost a year incorporating tremendous changes to the legacy Apache Ignite 1.x architecture. And all of that effort paid off. Our collective blood, sweat (and perhaps even a few tears) opened up new and exciting opportunities for the Apache Ignite project.
Have I piqued your interest about this new release yet? Let's walk through some of the main new features that have appeared under the hood of Apache Ignite 2.0.
Reengineered Off-Heap Memory Architecture.
The platform’s entire memory architecture was reengineered from scratch. In a nutshell, all of the data and indexes are now stored in a completely new manageable off-heap memory that has no issues with memory fragmentation, accelerates SQL Grid significantly and helps your application easily tolerate Java GC pauses.
Take a peek at the illustration below and try to guess what’s changed. Afterward, please read this documentation to see if your eye caught everything that’s new.
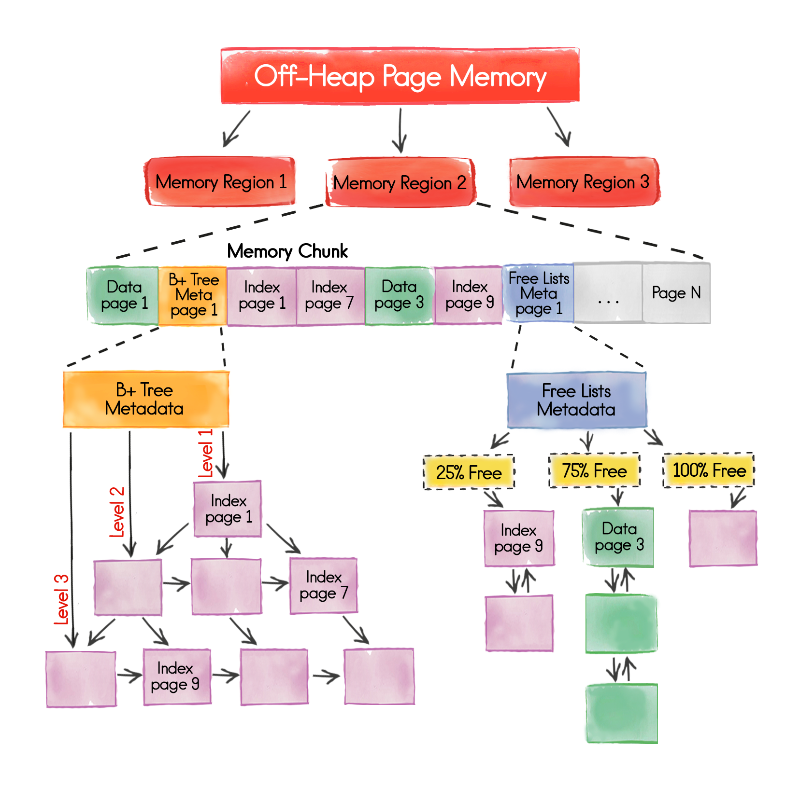
Here’s something extremely noteworthy: the architecture now integrates seamlessly with disk drives. Why do we care about this? Stay tuned!
Data Definition Language.
This release introduces support for Data Definition Language (DDL) as a part of its SQL Grid functionality. Now you can define -- and, what’s more important, alter -- indexes in runtime without the need to restart your cluster. Apache Ignite users have long awaited this feature! Even more exciting news: users can leverage this with standard SQL commands like CREATE or DROP index. This is only the beginning! Go to this page to learn more about current DDL support.
Machine Learning Grid Beta - Distributed Algebra.
Apache Ignite is about more than in-memory storage. And it’s not just one more product for distributed computations or real-time streaming. It's much, much more than that. It's a hot blend of well-integrated distributed and highly concurrent modules that turned Apache Ignite into what is today: A robust data-fabric and framework with the goal of making your application thrive and outperform even the best of expectations.
But there was one thing missing until now. Drumroll, please: machine-learning support!
With Apache Ignite 2.0 you can check project’s own distributed algebra implementation. The distributed algebra is the foundation of the entire component. And soon you can expect to get distributed versions of widely used regression algorithms, decision trees and more.
Spring Data Integration.
Spring Data integration allows the interaction of an Apache Ignite cluster using the well-known and highly adopted Spring Data Framework. You can connect to the cluster by means of Spring Data repositories and start executing distributed SQL queries as well as simple CRUD operations.
Rocket MQ
Are you using Rocket MQ in your project and need to push data from the Rocket to Ignite? Here is an easy solution.
Hibernate 5.
Hibernate L2 cache users have been anticipating support of Hibernate 5 on Apache Ignite for quite a long time. Apache Ignite 2.0 grants this desire. The integration now supports Hibernate 5 and contains a number of bug fixes and improvements.
Ignite.NET
Ignite.NET has been enhanced with an addition of a plugin system that allows the writing and embedding 3rd party .NET components into Ignite.NET.
Ignite.C++
The Ignite.C++ part of the community finally came up with a way to execute arbitrary C++ code on remote cluster machines.
This approach was initially tested for continuous queries. You can now register continuous queries' remote filters on any cluster node you like. Going forward you can expect support for the Ignite.C++ compute grid and more.
Want to learn more? Please join me June 7 for a webinar titled, “Apache® Ignite™: What’s New in Version 2.0.” I hope to see you there!
P.S. Just in case you can’t wait until June… here's a full list of the changes inside Apache Ignite 2.0.