Offheap Read-Path in Production - The Alibaba story
By Yu Li (HBase Committer/Alibaba), Yu Sun (Alibaba), Anoop Sam John (HBase PMC/Intel), and Ramkrishna S Vasudevan (HBase PMC/Intel)
Introduction
HBase is the core storage system in Alibaba’s Search Infrastructure. Critical e-commerce data about products, sellers and promotions etc. are all synced into HBase from various online databases. We query HBase to build and provide real time updates on the search index. In addition, user behavior data, such as impressions, clicks and transactions will also be streamed into HBase. They serve as feature data for our online machine learning system, which optimizes the personalized search result in real time. The whole system produces mixed workloads on HBase that includes bulkload/snapshot for full index building, batch mutation for real time index updates and streaming/continuous query for online machine learning. Our biggest HBase cluster has reached more than 1500 nodes and 200,000 regions. It routinely serves tens of millions QPS.
Both latency and throughput are important for our HBase deploy. From the latency perspective, it directly affects how quickly users can search an item after it has been posted as well as how ‘real-time’ we can run our inventory accounting. From the throughput perspective, it decides the speed of machine learning program processing, and thus the accuracy of recommendations made. What’s more, since data is distributed through the cluster and accesses are balanced, applications are sensitive to latency spikes on a single node, which makes GC a critical factor in our system servicing capability.
By caching more data in memory, the read latency (and throughput) can be greatly improved. If we can get our data from local cache, we save having to make a trip to HDFS. Apache HBase has two layers of data caching. There is what we call “L1” caching, our first caching tier – which caches data in an on heap Least Recently Used (LRU) cache -- and then there is an optional, “L2” second cache tier (aka Bucket Cache).
Bucket Cache can be configured to keep its data in a file -- i.e. caching data in a local file on disk -- or in memory. File mode usually is able to cache more data but there will be more attendant latency reading from a file vs reading from memory. Bucket Cache can also be configured to use memory outside of the Java heap space (‘offheap’) so users generally configurea a large L2 cache with offheap memory along with a smaller on heap L1 cache.
At Alibaba we use an offheap L2 cache dedicating 12GB to Bucket Cache on each node. We also backported a patch currently in master branch only (to be shipped in the coming hbase-2.0.0) which makes it so the hbase read path runs offheap end-to-end. This combination improved our average throughput significantly. In the below sections, we’ll first talk about why the off-heaping has to be end-to-end, then introduce how we back ported the feature from master branch to our customized 1.1.2, and at last show the performance with end-to-end read-path offheap in an A/B test and on Singles’ Day (11/11/2016).
Necessity of End-to-end Off-heaping
Before offheap, the QPS curve looked like below from our A/B test cluster

We could see that there were dips in average throughput. Concurrently, the average latency would be high during these times.
Checking RegionServer logs, we could see that there were long GC pauses happening. Further analysis indicated that when disk IO is fast enough, as on PCIe-SSD, blocks would be evicted from cache quite frequently even when there was a high cache hit ratio. The eviction rate was so high that the GC speed couldn’t keep up bringing on frequent long GC pauses impacting throughput.
Looking to improve throughput, we tried the existing Bucket Cache in 1.1.2 but found GC was still heavy. In other words, although Bucket Cache in branch-1 (branch for current stable releases) already supports using offheap memory for Bucket Cache, it tends to generate lots of garbages. To understand why end-to-end off-heaping is necessary, let’s see how reads from Bucket cache work in branch-1. But before we do this, lets understand how bucket cache itself has been organized.
The allocated offheap memory is reserved as DirectByteBuffers, each of size 4 MB. So we can say that physically the entire memory area is split into many buffers each of size 4 MB. Now on top of this physical layout, we impose a logical division. Each logical area is sized to accommodate different sized HFile blocks (Remember reads of HFiles happen as blocks and block by block it will get cached in L1 or L2 cache). Each logical split accommodates different sized HFile blocks from 4 KB to 512 KB (This is the default. Sizes are configurable). In each of the splits, there will be more that one slot into which we can insert a block. When caching, we find an appropriately sized split and then an empty slot within it and here we insert the block. Remember all slots are offheap. For more details on Bucket cache, refer here [4]. Refer to the HBase Reference Guide [5] for how to setup Bucket Cache.
In branch-1, when the read happens out of an L2 cache, we will have to copy the entire block into a temporary onheap area. This is because the HBase read path assumes block data is backed by an onheap byte array. Also as per the above mentioned physical and logical split, there is a chance that one HFile block data is spread across 2 physical ByteBuffers.
When a random row read happens in our system, even if the data is available in L2 cache, we will end up reading the entire block -- usually ~64k in size -- into a temporary onheap allocation for every row read. This creates lots of garbage (and please note that without the HBASE-14463 fix, this copy from offheap to onheap reduced read performance a lot). Our read workload is so high that this copy produces lots of GCs, so we had to find a way to avoid the need of copying block data from offheap cache into temp onheap arrays.
How was it achieved? - Our Story
The HBASE-11425 Cell/DBB end-to-end on the read-path work in the master branch, avoids the need to copy offheap block data back to onheap when reading. The entire read path is changed to work directly off the offheap Bucket Cache area and serve data directly from here to clients (see the details of this work and performance improvement details here [1], and [2]). So we decided to try this project in our custom HBase version based on 1.1.2 backporting it from the master branch.
The backport cost us about 2 people months, including getting familiar with and analysis of the JIRAs to port, fix UT failures, fixing problems found in functional testing (HBASE-16609/16704), and resolving compatibility issues (HBASE-16626). We have listed the full to-back-port JIRA list here [3] and please refer to it for more details if interested.
About configurations, since for tables of different applications use different block sizes -- from 4KB to 512KB -- the default bucket splits just worked for our use case. We also kept the default values for other configurations after carefully testing and even after tuning while in production. Our configs are listed below:
Alibaba’s Bucket Cache related configuration
How it works? - A/B Test and Singles’ Day
We tested the performance on our A/B test cluster (with 450 physical machines, and each with 256G memory + 64 core) after back porting and got a better throughput as illustrated below

It can be noted that now the average throughput graph is very much more linear and there are no more dips in throughput across time.
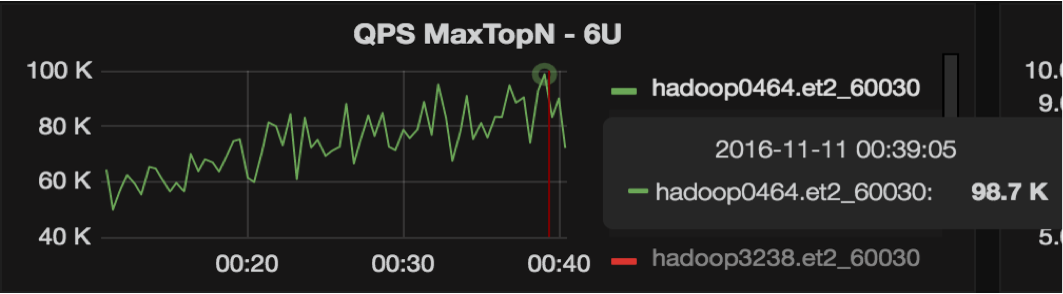
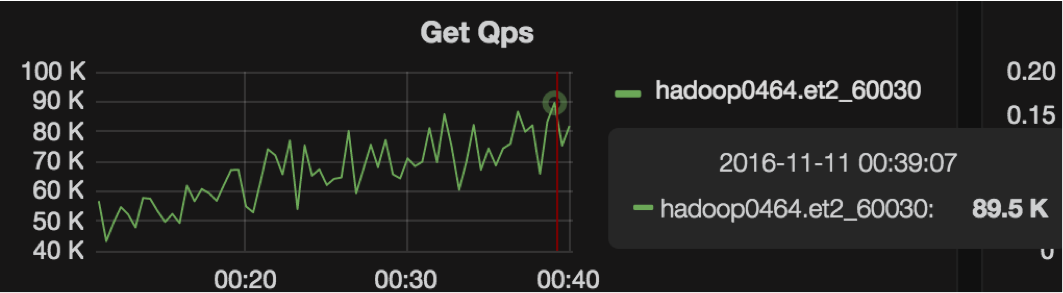
The version with the offheap read path feature was released on October 10th and has been online ever since (more than 4 months). Together with the NettyRpcServer patch (HBASE-15756), we successfully made it through our 2016 Singles’ Day, with peaks at 100K QPS on a single RS.
[1] https://blogs.apache.org/hbase/entry/offheaping_the_read_path_in
[2] http://www.slideshare.net/HBaseCon/offheaping-the-apache-hbase-read-path
[3] https://issues.apache.org/jira/browse/HBASE-17138
[4] https://issues.apache.org/jira/secure/attachment/12562209/Introduction%20of%20Bucket%20Cache.pdf