Running Hama K-Means in 5 minutes
Already you might know, the Apache Hama project provides a set of machine learning algorithms which can be applied in applications with very large scale data in multiple domains.
In this post, I explain how to run BSP-based K-Means algorithm using Apache Hama, assume that you have already installed Hama cluster and you have tested it.
1. Download a Iris data set [Data set Information].
2. Then, run KMeans using (TRUNK version is recommended):
% % $HAMA_HOME/bin/hama jar hama-examples-x.x.x.jar kmeans /tmp/kmeans.txt /tmp/result 10 3 ... [5.1, 3.5, 1.4, 0.2] belongs to cluster 2 [4.9, 3.0, 1.4, 0.2] belongs to cluster 2 [4.7, 3.2, 1.3, 0.2] belongs to cluster 2 [4.6, 3.1, 1.5, 0.2] belongs to cluster 2 [5.0, 3.6, 1.4, 0.2] belongs to cluster 2 ...
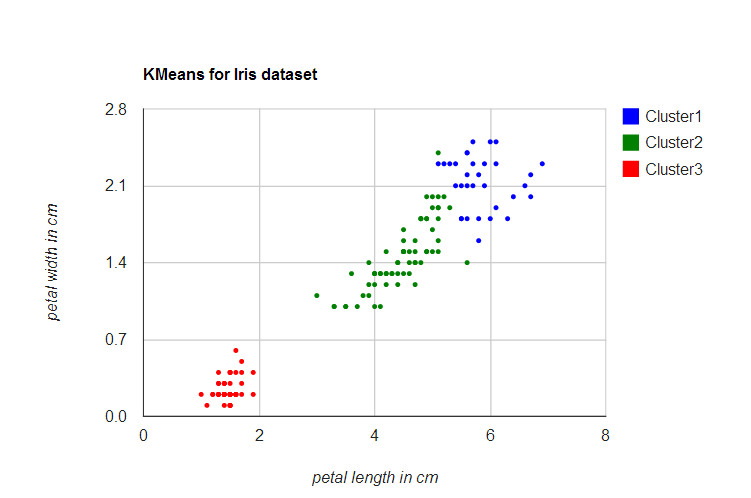
And Here's performance comparison with Mahout.
