All you wanted to know about Hadoop, but were too afraid to ask: genealogy of elephants.
Hadoop is taking central stage in the discussions about processing of the large amount of unstructured data.
With
raising the popularity of the system I found that people are really
puzzled with all the multiplicity of Hadoop versions; the small, yet
annoying differences introduced by different vendors; the frustration
when vendors are trying to lock up their customers using readily
available open source data analytic components on top of Hadoop, and on
and on.
So, after explaining who was born from whom for the 3rd time - and I
tell you, drawing neat pictures on a napkin in a coffee shop isn't my
favorite activity - I put together this little diagram below. Click on
it to inspect it in greater details. A warning: the diagram only
includes more or less significant releases of Hadoop and Hadoop-derived
systems available today. I don't want to waste any time on some obscure
releases or branches which never been accepted at any significant level.
The only exception is 0.21 which was a natural continuation of 0.20 and
predecessor of recently released 0.22.
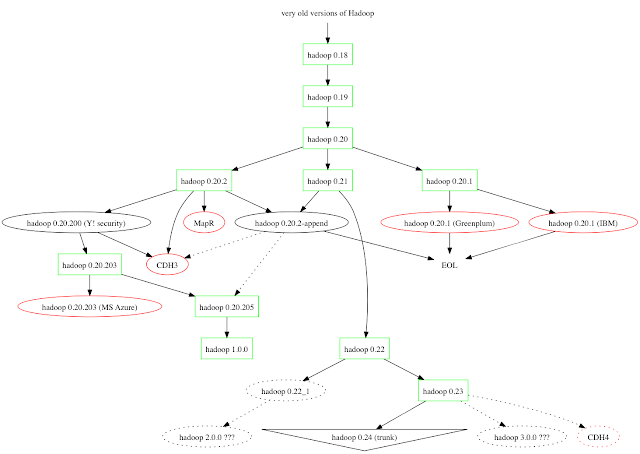
Some explanations for the diagram:
- Green rectangles designate official Apache Hadoop releases openly available for anyone in the world for free
- Black ovals show Hadoop branches that are not yet officially
released by Apache Hadoop (or might not be released ever). However, they
are usually available in the form of source code or tar-ball artifacts - Red ovals are for commercial Hadoop derivatives which might be based
on Hadoop or use Hadoop as a part of custom systems (like in case of
MapR). These derivatives can be or can be not compatible with Hadoop and
Hadoop data processing stack.
Once you're presented with the view like this it is getting
clear that there are two centers of the gravity in today's universe of
elephants: 0.20.2 based releases and derivatives; and 0.22 based
branches, future releases, and derivatives. Also, it becomes quite clear
which are likely to be sucked into a black hole.
The
transition from 0.20+ to 0.2[1,2] was real critical because of
introduced true HDFS append, fault injection, and code injection for
system testing. And the fact that 0.21 hasn't been released for a long
time, creating an empty space in the high demand environment. Even after
it did come out, it didn't get any traction in the community.
Meanwhile, HDFS append was very critical for HBase to move forward, so
0.20.2-append has been created to support the effort. A quite similar
story had happened to 0.22: two different release managers was trying to
get it out: first gave up, but the second has actually succeeded in
pulling an effort of a part of the community towards it.
As
you can see, HDFS append wasn't available in an official Apache Hadoop
release for some time (except for 0.21 with the earlier disclaimer).
Eventually it has been merged into 0.20.205 (recently dubbed as Hadoop
1.0) and that allows HBase to be nicely integrated with the official
Apache Hadoop without any custom patching process.
The
release of 0.20.203 was quite significant because it provided a heavily
tested Hadoop security, developed by Yahoo! Hadoop development team
(known as HortonWorks nowadays). Bits and pieces of 0.20.203 - even
before the official release - were absorbed by at least one commercial
vendor to add corporate grade Kerberos security to their derivatives of
Hadoop (as in case of Cloudera CDH3).
The diagram above clearly shows a few important gaps of the rest of commercial offerings:
- none of them supports Kerberos security (EMC, IBM, and MapR)
- unavailability of Hbase due to the lack of HDFS append in their
systems (EMC, IBM). In case of MapR you end up using a custom HBase
distributed by MapR. I don't want to make any speculation of the latter
in this article.
Apparently, the vacuum of significant releases between 0.20 and
0.22 appeared to be a major urge for Hadoop PMC and now - just days
after release of 1.0 - 0.22 got out. With 0.23 already going through
release process, championed by HortonWorks team. That release brings in
some interesting innovations like Federations and MapReduce 2.0.
Once
current alpha 0.23 (which might become Hadoop 2.0 or even Hadoop 3.0) is ready for
the final release I would expect new versions of commercial
distributions springing to live as it was the case before. At this point
I will update the diagram :)
If you can imagine the
variety of the other animals such as Pig, and Hive piling on top of
Hadoop, you would get astonished by the complexity of inter-component
relations and, more importantly, about intricacies of building a stable
data processing stack. This is why project BigTop has
been so important and popular ever since it sprung to life last year.
Here you can read about Bigtop's relation to Hadoop stack here.
